SWIN Transformer for Image Captioning
This project implements an end-to-end image captioning architecture that generates natural language descriptions of images by combining a SWIN Transformer visual encoder with a transformer decoder, built from scratch in TensorFlow/Keras and trained on the Flickr8k dataset.
Model Architecture
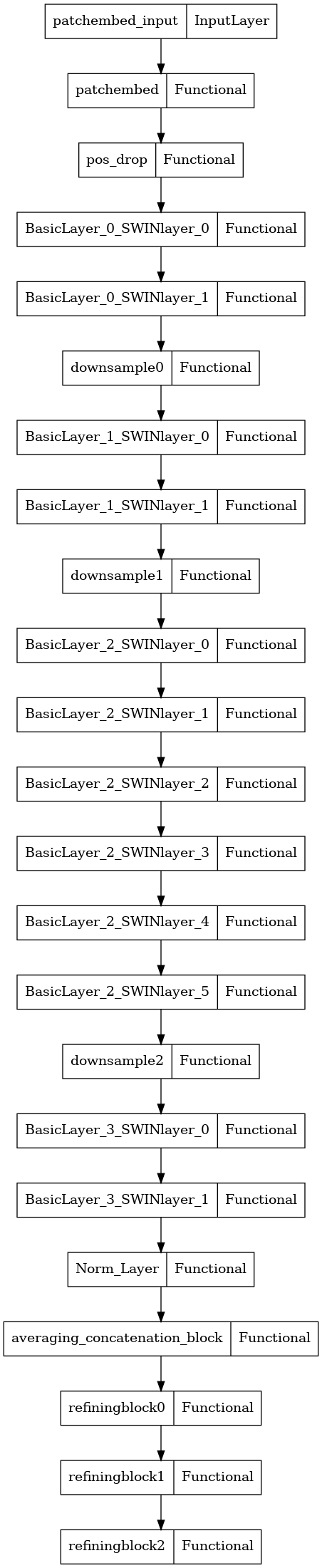
Architecture Components
SWIN Transformer Encoder
Input images are resized to 384×384 and processed by a Shifted Window Transformer — a hierarchical vision transformer that partitions the image into non-overlapping windows and applies self-attention within each window. Shifted windows in alternating layers allow cross-window information flow, building a multi-scale feature pyramid.
Refining Encoder Layers
Three additional encoder layers follow the SWIN backbone. Each combines:
- Local patch features from the SWIN output
- Global image features aggregated via pooling
- Cross-attention between local and global representations
This refines the visual features before they are passed to the decoder.
Prefusion Layer
Before decoding, word embeddings are fused with the global visual context via a Prefusion Layer, ensuring the decoder is conditioned on the image from the very first token.
Transformer Decoder
Six decoder layers with:
- Masked self-attention over the previously generated caption tokens
- Cross-attention over the encoded visual features
- Feed-forward sublayers with residual connections and layer normalization
Training
The model is trained with the Adam optimizer using a warmup + decay learning rate schedule, minimizing cross-entropy loss over the token predictions on Flickr8k caption-image pairs.
Summary
| Component | Details |
|---|---|
| Visual encoder | SWIN Transformer (384×384 input) |
| Feature refinement | 3 cross-attention refining encoder layers |
| Decoder | 6-layer transformer with masked self-attention |
| Dataset | Flickr8k (8,000 images, 5 captions each) |
| Framework | TensorFlow ≥2.8.0, Keras |
| Optimizer | Adam with warmup + decay schedule |